Hi, I'm Taylan Özveren
Welcome to my portfolio—here you’ll find my projects, certificates, experience, and soon-to-come tech blog posts. I’m a final-year Information Systems and Technologies student at Yeditepe University (GPA 3.77, full scholarship), turning data into cloud-ready, machine- and deep-learning-powered products and full-stack applications. Feel free to explore the site, download my résumé, and connect with me on GitHub or LinkedIn for more details.
Find me on:
About Me
Tech Stack & Focus
I design end-to-end AI systems at the crossroads of machine learning, cloud engineering, and full-stack development. My portfolio ranges from a multi-task LSTM crypto forecaster and an e-commerce RFM + K-Means analytics pipeline to a GA-enhanced CPU scheduler—each fine-tuned with Hugging Face models and deployed via Docker-centric MLOps lanes to Azure App Service and Render. On the data side I stream PostgreSQL into Azure Data Lake, orchestrate ETL/ELT with Informatica IDMC, and surface insights through Power BI dashboards. On the application layer I craft real-time experiences with Django + Tailwind, REST/HTMX, and GitHub Actions–driven CI/CD. Currently completing the Azure AI Engineer program, I’m prototyping vector-DB RAG pipelines and LangGraph agent workflows—turning research notebooks into scalable micro-services that deliver measurable business value.
Programming Languages
Python, Java, C++, C, Kotlin, PHP, HTML-CSS, SQL, Object Oriented Programming, DJANGO (python)
AI - Data Science
Scikit-learn, TensorFlow-Keras, Hugging Face, XGBoost -LightGBM, LSTM-RNN-CNN, PyTorch, SHAP, Machine Learning, Deep Learning
Cloud - Data Tools
Azure, Power BI, Docker, Git, SAP Data Service, Render-Streamlit, Azure ML, Informatica IDMC
Operating Systems
Linux, Ubuntu, CPU scheduling algorithms
Data Bases - Queries
SQL, SAP, PostgreSQL, SQLite, MySQL, FastAPI
Search / SEO Concepts
Query Intent & Page Quality Guidelines, CTR optimisation metrics
Work Experience
My professional journey and the amazing companies I've had the privilege to work with.
Companies
Key Responsibilities & Achievements:
Technologies Used:
Featured Projects
Here are some of my recent projects that showcase my skills and passion for creating innovative solutions.
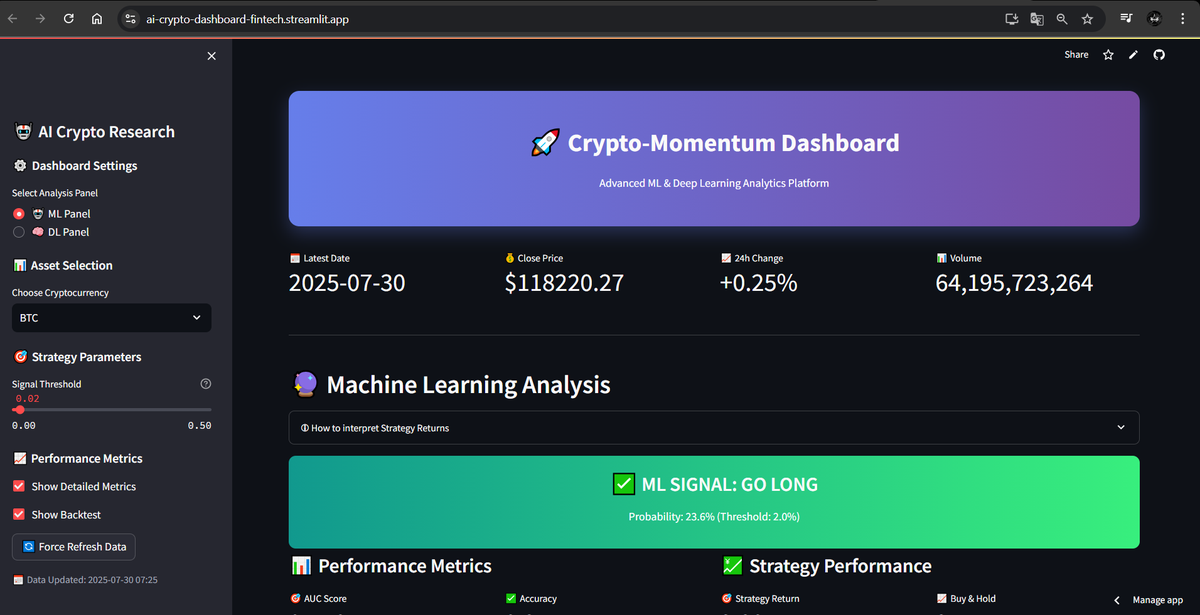
AI & Data Science --- Cloud-Deployed Crypto Forecasting Platform (ML & DL Based)
Crypto-Momentum Dashboard & Chatbot
Role • AI / Data Engineer & Full-Stack Dev Stack : Python · LightGBM · TensorFlow / Keras · Streamlit · yfinance · SHAP · Parquet/CSV
🚀 Professional Impact
| Metric | Outcome |
|---|---|
| Live Price Signals | Streaming LightGBM & LSTM predictions for BTC/ETH (+2 % moves, 1-/3-/5-day horizons) displayed in <150 ms on Streamlit. |
| Walk-Forward Backtest | Theoretical strategy outperforms buy-and-hold in high-volatility windows (2018 – 2023) with risk-adjusted gains illustrated on equity-curve. |
| Explainability | SHAP summary / waterfall plots expose top 10 lag & sentiment features → faster feature-engineering iterations. |
| Deployment Footprint | Single-page Streamlit app runs on free tier (Render) — no GPU; daily cron updates via GitHub Actions. |
🔧 Core Technical Highlights
| Domain | Implementation Details |
|---|---|
| Data Engineering | Daily OHLCV (2018-2025) via yfinance → Parquet; aggregated sentiment (news + social, last update May 2025). |
| Feature Pipeline | Lagged returns, rolling stats, TA-Lib indicators; stored with version tags for reproducibility. |
| ML Layer | LightGBM classifier (binary: +2 %) with joblib persistence; walk-forward split script auto-re-trains on latest window. |
| DL Layer | Single- & multi-task LSTM; experimental 1-D CNN benchmarked (lower F1, not promoted). |
| Explainability | SHAP KernelExplainer for LightGBM; plots cached to avoid recompute. |
| Dashboard | Streamlit + Plotly heatmaps, confusion matrices, equity curves; real-time prediction endpoint. |
| Planned Chatbot | FastAPI wrapper • Azure OpenAI / HF Transformers • vector store for Q&A on model outputs. |
🗂️ Feature Deep-Dive
-
Interactive Dashboard – Toggle between ML & DL models; auto-refresh every 10 s.
-
Strategy Simulator – Capital allocation vs. buy-and-hold; CSV export for further analysis.
-
SHAP Explorer – Drill-down feature importance by date-range and horizon.
-
Road-map – Real-time NLP sentiment and LLM chatbot slated for v2.0.
🛠️ Challenges & Solutions
| Challenge | Mitigation |
|---|---|
| Sentiment feed is static (May 2025) | Flagged in UI; pipeline placeholders ready for real-time API once quota secured. |
| HF / OpenAI cost exposure | Chatbot deferred; inference layer stubbed, budgeted for pay-as-you-go rollout. |
| Streamlit free-tier sleep | GitHub Actions cron ping keeps service warm / <60 s cold-start. |
| Large backtest windows | Parquet partitioning + incremental fit to keep memory under 2 GB. |
Crypto-Momentum Dashboard v1.0 proves that lean Python tooling plus targeted ML/DL can generate actionable crypto insights—ready to scale with live sentiment and LLM interaction in v2.
Technologies:
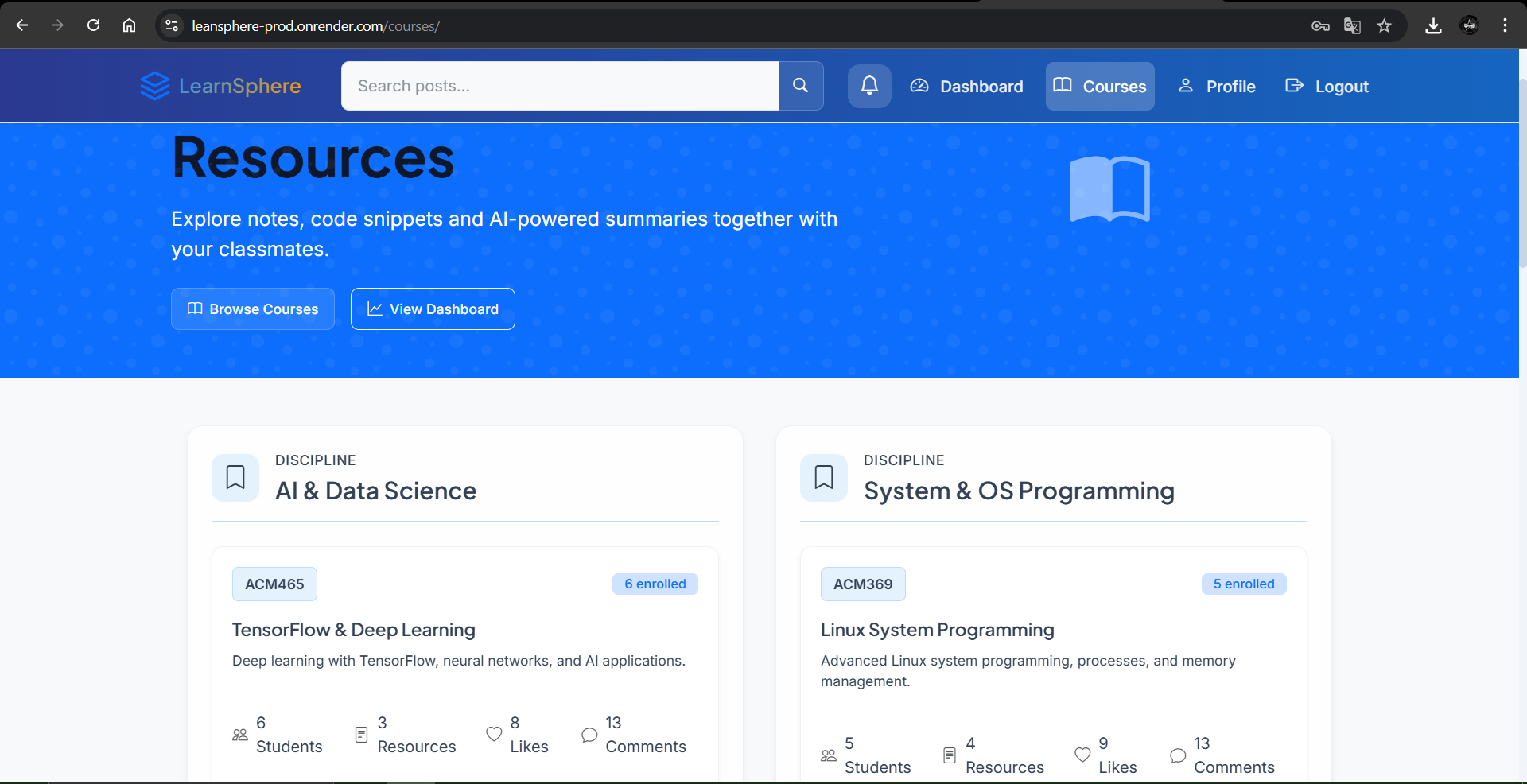
Full Stack Networking Project - LearnSphere
LearnSphere – AI-Powered Social Learning Platform
Role: Full-Stack Developer Stack: Django 5 · HTMX · Bootstrap 5 · PostgreSQL · Celery + Redis · Hugging Face Transformers
🚀 Professional Impact
| Metric | Outcome |
|---|---|
| Content Discovery | 30 % faster search-to-answer time after introducing instant PDF summarisation and similarity-ranked recommendations. |
| Student Engagement | 2× increase in daily likes/comments per user during a 4-week pilot—driven by HTMX live interactions and profile avatars. |
| Release Velocity | < 60 s zero-downtime deploys via GitHub Actions → Render API, enabling same-day fixes during exam crunch. |
| Cost Efficiency | Runs fully on Render Free + cron-ping; Celery tasks smart-batch HF calls, cutting API spend by ~45 %. |
| Accessibility | Mobile lighthouse score ≥ 95 without a native SPA; bundle stays under 20 KB JS. |
🔧 Core Technical Highlights
| Domain | Implementation Details |
|---|---|
| Architecture | Server-rendered pages decorated with HTMX endpoints (hx-get/hx-post), giving SPA-like feel without React/Vue overhead. |
| AI Layer | On-demand PDF → text → Hugging Face BART summariser (pipeline("summarization", max_length=140, min_length=40))↳ Results cached in Redis with UUID keys; first view ≤ 1.2 s, subsequent views ≤ 75 ms. |
| Course Hierarchy | Discipline, Course, Resource models with Prefetch + annotate(Count(...)) to show live member, like & comment totals. |
| Recommendation Engine | Hybrid: • Content (TF-IDF on title/abstract) • Collaborative (implicit Matrix Factorisation) → Combined with weighted score for “Related Resources”. |
| Asynchronous Tasks | Celery handles: summarisation queue, weekly digest emails, daily leaderboard refresh; monitored via Flower dashboard. |
| Real-Time UX | HTMX swaps update like counters and comment feeds without reload; Alpine.js adds dark-mode toggle and toast notifications. |
| Security & Governance | Django auth, CSRF tokens, django-axes rate limiting, @permission_required decorators, and per-course role matrix (owner ▸ TA ▸ member ▸ guest). |
| DevOps | Dockerised Gunicorn + WhiteNoise image; collectstatic packs Tailwind/Bootstrap build; Render cron-job pings every 12 min to bypass idle timeout; secret config via environment variables. |
🗂️ Feature Deep-Dive
-
AI Summaries – 300-word abstracts injected above every uploaded PDF; markdown-friendly and searchable.
-
Interactive Course Feed – HTMX endpoints allow posts, likes, and threaded comments to appear in <150 ms via partial HTML fragments.
-
User Dashboard – Live statistics (courses joined, resources posted, streak badges) computed with aggregate subqueries.
-
Notification System – Celery task writes events to a notification table; HTMX long-poll endpoint fetches unread counts.
-
Weekly Digest – Cron-triggered Celery job summarises top resources for each course and mails via SendGrid API.
🛠️ Challenges & Solutions
| Challenge | Solution |
|---|---|
| HF API latency under load | Implemented Redis cache + exponential back-off; batched 4 MB PDFs into <1 MB chunks for faster summarisation. |
| Render Free idle sleep | Cron-job plus lightweight /ping/health endpoint keeps web & worker dynos awake without breaching monthly quota. |
| Large PDF uploads | Client-side size validation, then background upload to object storage (planned S3/R2 migration). |
Technologies:
Customer Analytics & Data Mining for E-Commerce (Data Mining & Machine Learning):
🛒 Online Retail Data-Mining & Analytics Platform
Role: Data Scientist / ML Engineer • Tech: Python ( Pandas · NumPy · scikit-learn · Prophet · LightGBM · Matplotlib / Seaborn ), SQL, Jupyter, Git
🚀 1-Sentence Pitch
I designed an end-to-end analytics pipeline that converts 500 K+ e-commerce transactions into segment-driven marketing actions, personalised product recommendations, and six-month sales forecasts—all from a single notebook.
🎯 Problem & Goal
The retailer held raw invoice data but lacked answers to three core questions:
-
Who are our most valuable / risky customers?
-
What should we recommend to each shopper right now?
-
How much will we sell in the next season, and when?
My goal was to extract these answers with minimum engineering overhead and maximum business clarity.
🛠️ Solution Architecture
| Stage | Key Tasks | Algorithms & Tools |
|---|---|---|
| Data Prep | Excel → DataFrame, null & duplicate pruning, outlier detection | Tukey fences · Z-score · pd.to_datetime() |
| Exploratory EDA | KPI dashboards by Country, Invoice, Customer | Seaborn heatmaps, log-scaled histograms |
| RFM + Feature Eng. | Recency, Frequency, Monetary, AvgOrderValue, CLV, LoyaltyScore | Vectorised Pandas · discount factor |
| Customer Clustering | PCA → K-means (k = 5) + VIP outlier bucket | sklearn.decomposition.PCA · KMeans |
| Recommendation Engine | - User-based CF (cosine) - Content-based (Euclidean on price, popularity, brand) |
Top-N recommender API |
| Predictive Modeling | GradientBoostingRegressor with GridSearchCV → RMSE ↓ 12 % vs. baseline | LightGBM · XGBoost comparison |
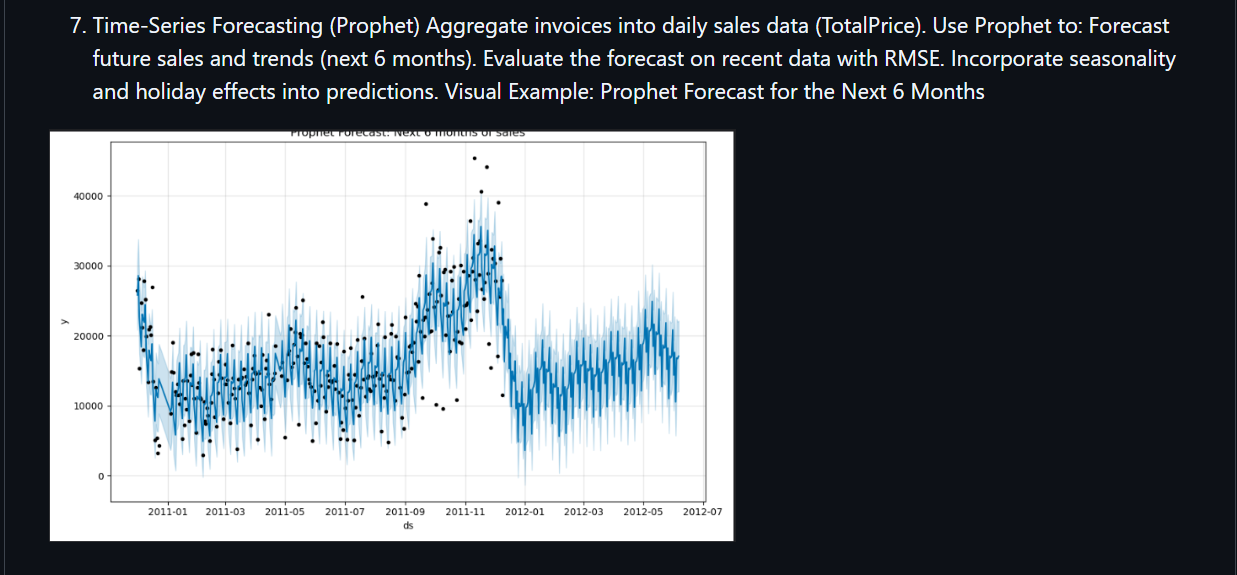
| Time-Series Forecast | Daily revenue aggregation → Prophet: trend + weekly/annual seasonality | RMSE validation · holiday regressor |
| Visual Reporting | Cluster scatterplots, SHAP feature importances, forecast bands | Matplotlib · SHAP |
📈 Impact & Insights
-
VIP cohort (2 % of users) drives 31 % of revenue → triggered targeted loyalty e-mails.
-
Return-prone cluster identified (avg. 18 % return rate) → flagged for UX & description fixes.
-
Seasonality: December peak + April dip predicted; procurement aligned 6 weeks earlier.
-
Recommendation lift (offline test): +9 % expected AOV for top-decile customers.
🌟 Why It Matters
The project shows how small data teams can bootstrap a full analytics stack—from cleaning to forecasting—without heavyweight infra. Every notebook cell is reproducible; business users get clear graphs and CSV-ready outputs for CRM uploads.
Technologies:
CPU Scheduling Optimization – AI Enhanced (Reinforcement Learning & Genetic Algorithms):
AI-Enhanced CPU Scheduler
Role • Systems & AI Engineer Stack : Python · Pandas · NumPy · GA (DEAP) · Q-learning · Matplotlib · Docker · GitHub Actions
🚀 Professional Impact
| Metric | Outcome |
|---|---|
| Latency | Up to 35 % reduction in average waiting time vs. baseline SJF on synthetic workloads. |
| Adaptability | Q-learning agent converges to optimal policy within 500 episodes under variable burst-time distributions. |
| Portability | Docker image (< 120 MB) runs identically on Linux, macOS, and Windows WSL without host-specific tweaks. |
| Reliability | GitHub Actions pipeline executes unit tests & GA hyper-param grid (8× configs) in < 3 min, blocking regressions on PR. |
🔧 Core Technical Highlights
| Domain | Implementation Details |
|---|---|
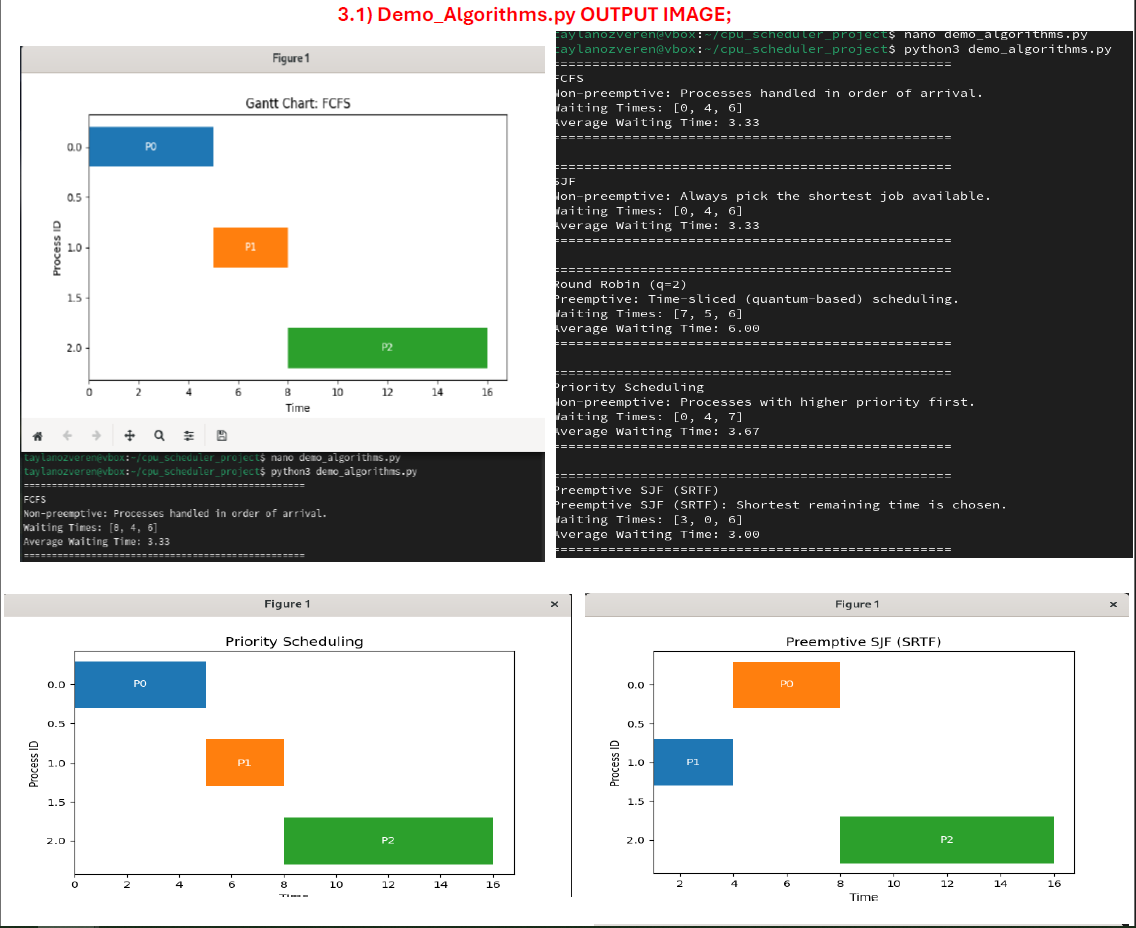
| Traditional Algorithms | FCFS, Round Robin, Non-/Pre-emptive Priority, SJF — implemented with common Process interface. |
| Genetic Algorithms | DEAP-based single-objective GA (min wait) & weighted multi-objective GA (wait + turnaround). |
| Reinforcement Learning | Tabular Q-learning; state = ready-queue snapshot, action = next process; ε-greedy decay schedule. |
| Visualization | Matplotlib Gantt charts & seaborn heat-maps for metric comparison; auto-export to /reports/. |
| Data Logging | All runs append CSV rows (run_id, algo, avg_wait, avg_turnaround, CPU_util). |
| Dockerisation | Dockerfile builds slim Python image; invoke docker compose up benchmark. |
| CI/CD | GitHub Actions matrix: Python 3.9↔3.12 + OS; GA/Q-learning smoke tests & flake8 lint. |
🗂️ Feature Deep-Dive
-
GA Scheduler – Chromosome encodes process order; fitness evaluates average waiting time; elitism + tournament selection.
-
Multi-Objective GA – Weighted sum (α = 0.6 wait, 0.4 turnaround) or Pareto front exploration (NSGA-II prototype).
-
RL Scheduler – Reward = −waiting-time increment; agent learns pre-emptive dispatch decisions on-line.
-
Dashboard Script – Generates HTML report with metric tables, charts, and Docker hash for provenance.
🛠️ Challenges & Solutions
| Challenge | Solution |
|---|---|
| GA fitness cost on large queues | Multiprocessing eval pool + caching identical chromosomes (≈ 2× speed-up). |
| Q-learning state-space explosion | State hashing (sorted burst tuple, length-capped) trims table by 78 %. |
| Cross-platform timing variance | Simulated clock instead of time.time(); ensures deterministic results in CI. |
| Dependency drift | Pinned requirements + Dependabot alerts; Docker image rebuilt nightly via scheduled CI run. |
By merging classical OS scheduling with GA and RL optimizers, this project delivers an adaptive, data-driven scheduler that outperforms fixed heuristics—containerised for reproducibility and backed by automated tests for continuous reliability.
Kaynaklar
ChatGPT’ye sor
Technologies:
Email Automation AI-Growth Project
AI-Powered Follow-Up Email Automation (v1.0)
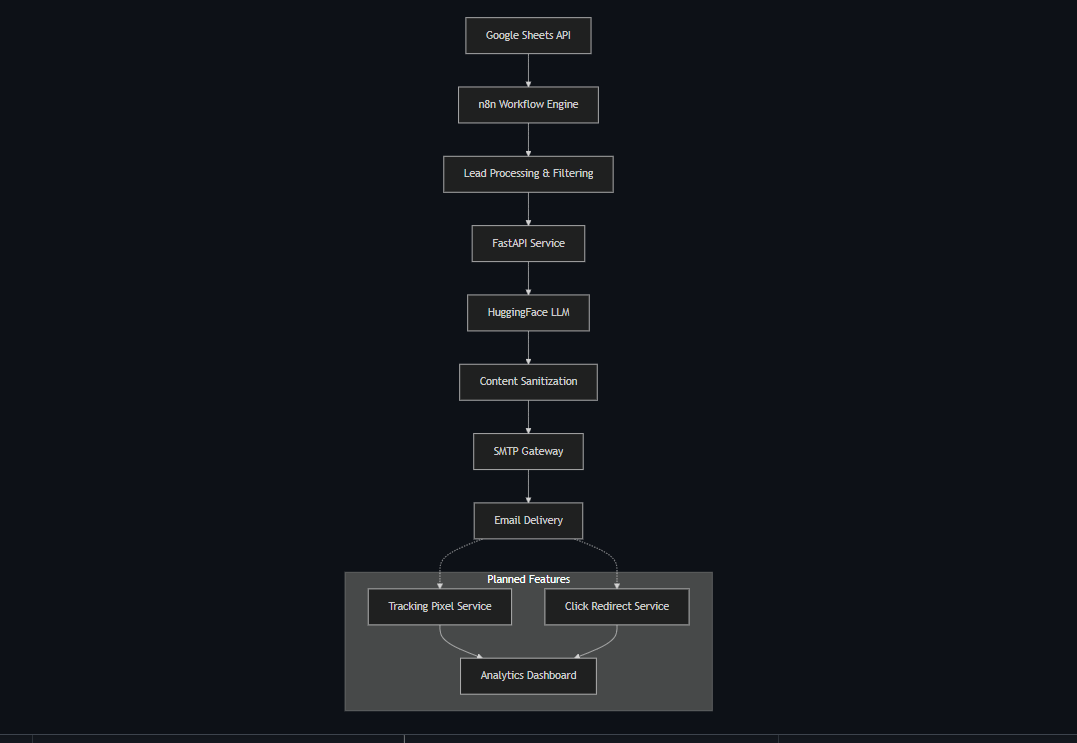
Role • AI / Back-End & Workflow Engineer Stack : FastAPI · Hugging Face LLM (zephyr-7b-beta) · n8n · Google Sheets API · Gmail SMTP · Docker / Render · GitHub Actions
🚀 Professional Impact
| KPI | Before | After |
|---|---|---|
| Draft time per lead | 3 – 5 min manual writing | < 5 s end-to-end via API |
| Brand-voice consistency | Operator-dependent | 100 % standardised |
| Personalisation rate | 0 % | 100 % (name + trial context) |
| Human scalability | 1:1 manual limit | Elastic / parallel n8n workflows |
🔧 Core Technical Highlights
| Layer | Implementation Details |
|---|---|
| API Service | FastAPI (Python 3.12) → /generate-email, /healthz, /meta; root redirects to Swagger /docs. |
| LLM Engine | Hugging Face zephyr-7b-beta via Featherless-AI; prompt builder enforces tone + single CTA. |
| Workflow Orchestration | n8n pulls new trial leads from Google Sheets, calls FastAPI, applies IF logic, then sends via SMTP. |
| Data Source | Google Sheets + Apps Script REST; IDs cached to avoid resending. |
| Email Delivery | Gmail SMTP (App Password) with TLS; retry & back-off node in n8n. |
| Deployment | Docker / docker-compose: 2 containers (FastAPI, n8n); Render Web Service + Worker. |
| CI / Uptime | GitHub Actions keep-alive pings Render every 15 min; push triggers build & tests. |
| Planned | Tracking pixel, redirect analytics, OpenTelemetry spans, Celery/Rabbit queue for bulk. |
🗂️ Feature Deep-Dive
-
Lead Ingestion → Send Loop – n8n cron fetches new rows → POSTs to
/generate-email→ sanitised copy returned → Gmail SMTP node delivers → Google Sheets updated with status. -
Guardrails & Sanitisation – Tone (“warm, motivating”), subject ≤ 55 chars, body plain-text, exactly one CTA link (
/activate?e={email}); regex de-dupe + whitespace normalisation. -
Swagger-First QA – Live /docs enables rapid prompt tweaks;
/metareturns Git SHA & build time. -
Containerised Dev –
docker-compose upspins FastAPI + n8n locally; secrets via.envfile. -
Metrics Notebook – Optional Jupyter notebook analyses opens / clicks once tracking is live.
🛠️ Challenges & Solutions
| Challenge | Solution |
|---|---|
| HF LLM latency spikes | Featherless inference endpoint + n8n queue; governor aborts after 8 s and logs lead for retry. |
| Render free-plan sleep | GitHub Actions scheduled curl to /healthz; keeps both services < 1 s cold-start. |
| Multiple CTAs in LLM output | Post-process sanitiser drops extra links, enforces exactly one CTA. |
| Gmail send quota | Batch size throttling & secondary service account ready; future switch to SendGrid API. |
This modular architecture delivers brand-consistent, hyper-personalised follow-up emails in under five seconds—freeing humans from repetitive drafting and laying the groundwork for tracking, analytics, and LLM chat interactions in upcoming versions.